laravel缓存
2018-10-31 09:07:00 来源:admin 点击:1733
缓存是web开发中重要的一部分,我相信很多人和我一样,经常忽略这个问题。 随着工作经验的累积,我已经意识到缓存是多么的重要,这里我通过 Scotch 来解释一下它的重要性。
通过观察发现,Scotch每天按照计划发布文章,然而,上一次发布文章的24小时内,新的文章不会被放出,因此,登陆页面上的数据将保持24小时不变。 换句话说,在24小时内( 更准确的说是22-23个小时)向数据库请求文章数据是没有意义的。
缓存可以很好的解决这个问题,当遇到一个页面请求时,我们可以把结果缓存22个小时,只要在这个时间内通过控制器请求的数据,都是缓存中的数据,直到缓存超时。
在
下面我们来看看Laravel 中缓存的基本用法,然后看一个简单的例子,试试缓存到底能带来多大的加速。
在 Laravel 中缓存的基本用法
Laravel 使得我们可以轻松地转换出我们想要生成缓存的方式。我们很容易修改缓存驱动方式。只需到 config / cache.php 来查看可用的驱动程序:
apc
array
database
file
memcached
redis
你可以在 .env 文件中修改缓存驱动:
CACHE_DRIVER=file
你可以继续尝试修改它们而不用担心配置,因为它默认驱动是
file。
Cache facade 暴露了很多静态方法来创建,更新,获取,删除和检查缓存内容的存在。让我们在构建演示应用程序之前先了解一下这些方法。
建立/更新缓存值
我们使用 put() 方法来新增或更新缓存值。该方法必须使用 3 个参数:
键名键值过期时间单位分钟
例如:
Cache::put('key', 'value', 10); 键名 是缓存的唯一标识,需要时要用它来获取值。
此外,我们也可以用 remember() 方法自动获取和更新一个缓存值。该方法首先检查 键名 是否存在,如果已经创建则返回结果。否则它会创建新的 键名 ,并用闭包返回结果进行赋值,就象下面:
Cache::remember('articles', 15, function() { return Article::all();
});参数 15 是要缓存的分钟数。这样的话,我们甚至根本不必检查缓存是否过期。Laravel 不仅会替我们打理,而且会获取或重新生成该缓存,不需要我们显式地告诉它如何操作。
检索缓存值
缓存的值可以通过 get() 方法去获取,这个方法接受一个参数 key :
Cache::get('key');检查是否已存在key
有时候在更新或者取回缓存值之前判断这个缓存的key是否存在是很有必要的,使用 has() 方法就可以实现:
if (Cache::has('key')){ Cache::get('key');
} else { Cache::put('key', $values, 10);
}删除缓存值
删除缓存值可以用 forget() 方法并把需要删除的 key 作为参数传进去:
Cache::forget('key');我们也可以检索缓存值并删除它。我喜欢把这个称为一次性缓存:
$articles = Cache::pull('key');我们还可以使用以下命令在缓存过期前就把所有缓存清楚掉:
php artisan cache:clear
一个例子
这是一个简单的演示,主要是为了说明是否使用缓存对请求响应所需要时间的影响,为了让你能更直接的了解,我建议你跟着教程自己来 构建 一个 Laravel 例子。
模型和表迁移
使用下面命令新建一个 Article 模型:
php artisan make:model Article -m
-m 参数会自动创建一个 migration ,所以无需再使用 create migration 命令了,这个命令会创建 App/Article.php 和 database/migrations/xxxx_xx_xx_xxxxxx_create_articles_table.php 文件。
修改你的 migration 文件并添加以下两行:
public function up() {
Schema::create('articles', function (Blueprint $table) {
$table->increments('id'); // add the following
$table->string("title");
$table->string("content");
$table->timestamps();
});
}然后我们就可以用以下命令迁移我们的数据库了:
php artisan migrate
填充数据库
接下来我们需要填充文章的数据库表,在 database/seeds/DatabaseSeeder.php 中,修改 run() 如下所示:
public function run() {
Model::unguard(); // use the faker library to mock some data
$faker = Faker::create(); // create 30 articles
foreach(range(1, 30) as $index) {
Article::create([ 'title' => $faker->sentence(5), 'content' => $faker->paragraph(6)
]);
}
Model::reguard();
}Laravel中包含 Faker 库用以快速生成假数据,我们可以使用PHP的 range() 方法去生成30条假数据。
接下来我们就可以通过这条 artisan 命令去填充数据库了:
php artisan db:seed
创建文章控制器
接下来,我们可以创建一个处理请求和缓存的控制器,首先它是空的:
php artisan make:controller ArticlesController
...然后我们增加一个路由 app/Http/routes.php 指向这个文章控制器的 index 方法:
Route::group(['prefix' => 'api'], function() { Route::get('articles', 'ArticlesController@index');
});现在我们的数据库都是用样本数据建立起来的,我们可以进行测试了。
未使用缓存的响应
让我们看看我们传统的控制器方法是什么样的,没有缓存,处理响应需要多长时间,在 index() 方法中,返回文章的资源数据:
public function index() {
$articles = Articles::all(); return response()->json($articles);
}你也可以使用 Postman 去请求(http://localhost/api/articles) 或者直接用浏览器打开,你就可以看到如下所示。
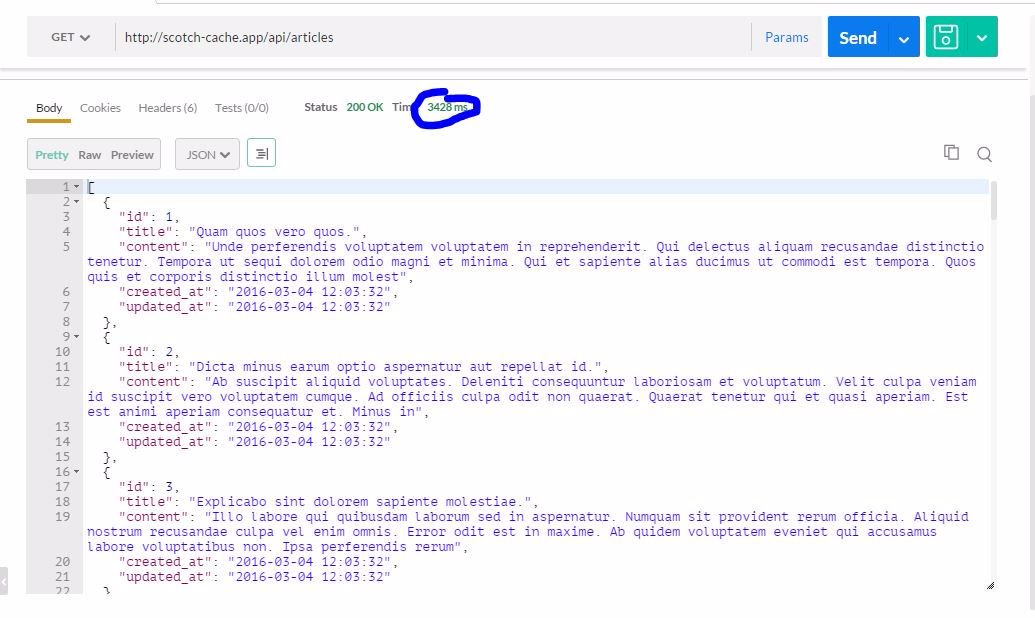
请注意在本地开发服务器上完成此请求所花费的时间。
从缓存中返回的响应
现在让我们尝试使用缓存,看看数据响应所花费的时间是否会有显着差异。修改 index()方法为:
public function index() {
$articles = Cache::remember('articles', 22*60, function() { return Article::all();
}); return response()->json($articles);
}现在我们使用 remember() 方法缓存了文章,缓存时间为 22 小时,再次运行并观察所花费的时间,可以看我的截图:
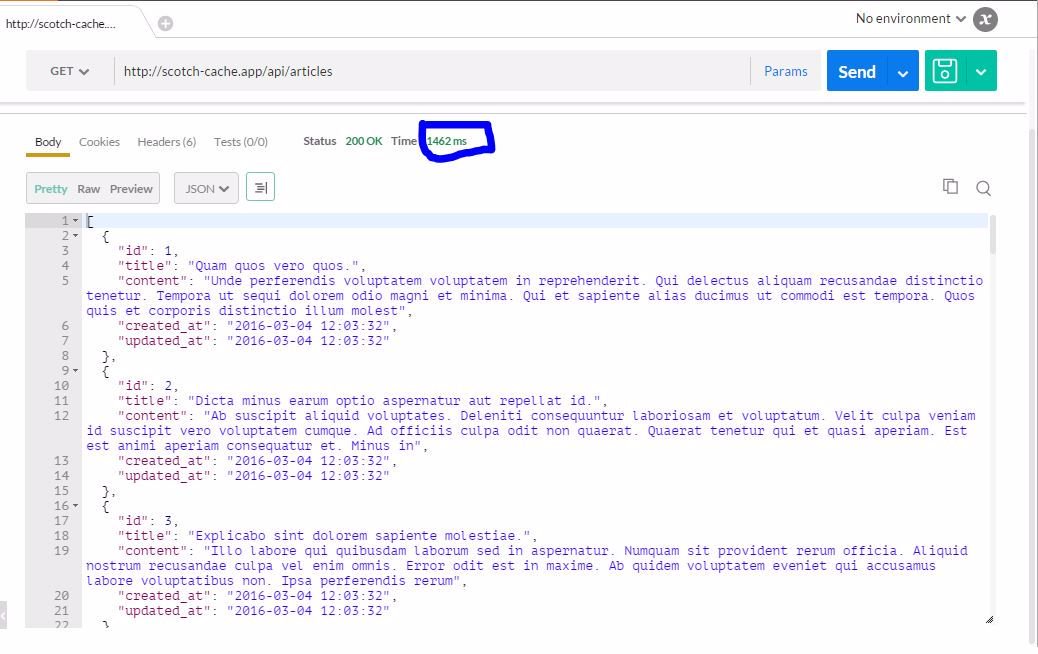
结果和建议
在我的标准开发环境中测试得出,使用缓存时产生响应所需的时间比没有使用的时候要少:
未使用缓存
| Server Hits | Time |
|---|---|
| 1st | 4478ms |
| 2nd | 4232ms |
| 3rd | 2832ms |
| 4th | 3428ms |
| Avg | 3742ms |
使用缓存 (File 驱动)
| Server Hits | Time |
|---|---|
| 1st | 4255ms |
| 2nd | 3182ms |
| 3rd | 2802ms |
| 4th | 3626ms |
| Avg | 3466ms |
使用缓存 (Memcached 驱动)
| Server Hits | Time |
|---|---|
| 1st | 3626ms |
| 2nd | 566ms |
| 3rd | 1462ms |
| 4th | 1978ms |
| Avg | 1908ms :) |
使用缓存 (Redis 驱动)
这里需要通过 composer 安装 predis/predis 包
| Server Hits | Time |
|---|---|
| 1st | 3549ms |
| 2nd | 1612ms |
| 3rd | 920ms |
| 4th | 575ms |
| Avg | 1664ms :) |
是不是很酷呢?这里有两点需要注意:
即使使用了缓存,第一次请求响应还是需要比较多的时间,因为当第一次请求的时候缓存里面还是空的。
与 file 驱动相比,Memcached 和 Redis 的速度更快,所以建议在项目较大时使用外部缓存驱动。
结论
使用文件、数据库作为驱动,两者在速度上没有很明显的区别。但是如果我们使用第三方服务作为驱动, 可以很明显地看到性能提升。所以投资高速缓存是值得的。